


git clone https://github.com/crawlab-team/examples
cd examples/docker/basic
docker-compose up -dversion: '3.3'
services:
master:
image: crawlabteam/crawlab:latest
container_name: crawlab_example_master
environment:
CRAWLAB_NODE_MASTER: "Y"
CRAWLAB_MONGO_HOST: "mongo"
volumes:
- "./.crawlab/master:/root/.crawlab"
ports:
- "8080:8080"
depends_on:
- mongo
worker01:
image: crawlabteam/crawlab:latest
container_name: crawlab_example_worker01
environment:
CRAWLAB_NODE_MASTER: "N"
CRAWLAB_GRPC_ADDRESS: "master"
CRAWLAB_FS_FILER_URL: "http://master:8080/api/filer"
volumes:
- "./.crawlab/worker01:/root/.crawlab"
depends_on:
- master
worker02:
image: crawlabteam/crawlab:latest
container_name: crawlab_example_worker02
environment:
CRAWLAB_NODE_MASTER: "N"
CRAWLAB_GRPC_ADDRESS: "master"
CRAWLAB_FS_FILER_URL: "http://master:8080/api/filer"
volumes:
- "./.crawlab/worker02:/root/.crawlab"
depends_on:
- master
mongo:
image: mongo:4.2
container_name: crawlab_example_mongo
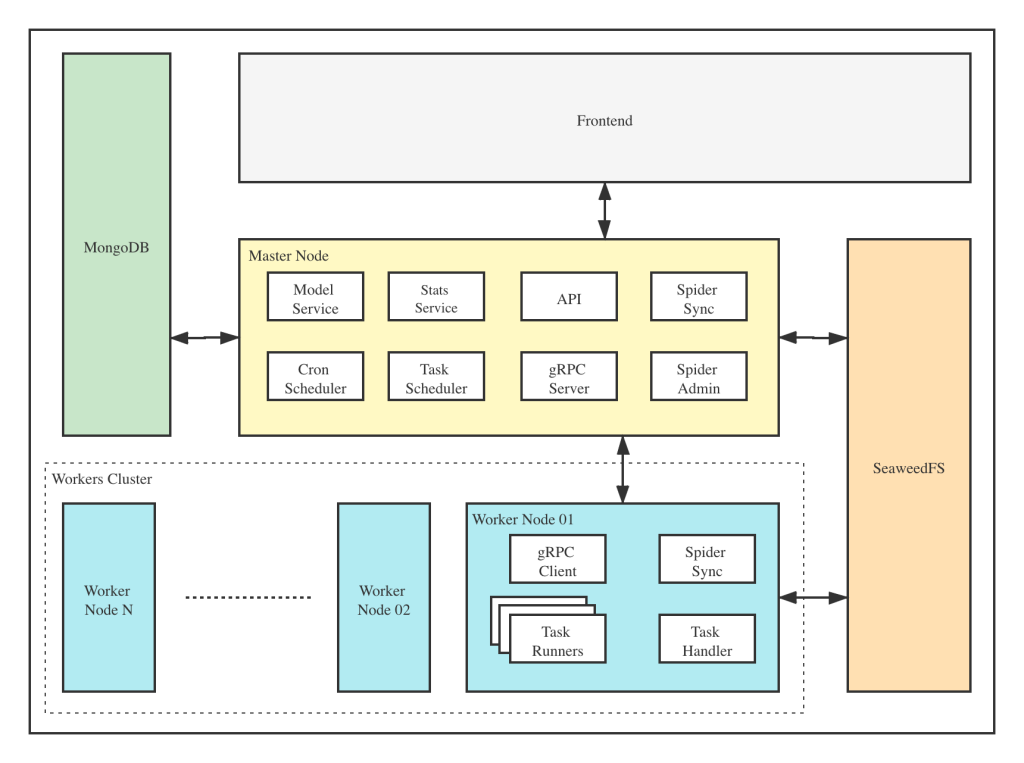
restart: always前端应用程序与主节点交互,主节点与MongoDB、SeaweedFS和工作节点等其他组件通信。主节点和工作节点通过gRPC(RPC框架)相互通信。任务由主节点中的任务调度程序模块进行调度,并由工作节点的任务处理程序模块接收,工作节点在任务运行器中执行这些任务。任务运行器实际上是运行spider或crawler程序的进程,也可以通过gRPC(集成在SDK中)将数据发送到其他数据源,例如MongoDB。
主节点
主节点是Crawlab体系结构的核心。它是Crawlab的中央控制系统。
主节点提供以下服务:
任务调度;
工人节点管理与沟通;
蜘蛛部署;
前端和API服务;
任务执行(可以将主节点视为工作节点)
主节点与前端应用程序通信,并向辅助节点发送爬网任务。同时,主节点将蜘蛛上传(部署)到分布式文件系统SeaweedFS,供工作节点同步。
Worker节点
辅助节点的主要功能是执行爬网任务、存储结果和日志,并通过gRPC与主节点通信。通过增加工作节点的数量,Crawlab可以水平扩展,并且可以将不同的爬网任务分配给不同的节点执行。
MongoDB
MongoDB是Crawlab的操作数据库。它存储节点、蜘蛛、任务、时间表等的数据。任务队列也存储在MongoDB中。
SeaweedFS
SeaweedFS是由Chris Lu编写的一个开源分布式文件系统。它可以在分布式系统中稳健地存储和共享文件。在Crawlab中,SeaweedFS主要充当文件同步系统和存储任务日志文件的地方。
前端
前端应用程序基于流行的基于Vue 3的UI框架Element-Plus构建。它与主节点上托管的API交互,并间接控制工作节点。
与其他框架的集成
Crawlab SDK提供了一些帮助方法,使您更容易将蜘蛛集成到Crawlab中,例如保存结果。
作者:JackLee,如若转载,请注明出处:https://www.wlwlm.com/article/5726.html